
介绍python中引用与对象,可变数据类型与不可变数据类型,值传递,变量和内存管理等方面的内容
引用与对象
Python 中,一切皆对象。 每个对象由:标识(identity)、类型(type)、value(值) 组成。
- 标识用于唯一标识对象,通常对应于对象在计算机内存中的地址。使用内置函数 id(obj)可返回对象 obj 的标识。
- 类型用于表示对象存储的“数据”的类型。类型可以限制对象的取值范围以及可执行的 操作。可以使用 type(obj)获得对象的所属类型。
- 值表示对象所存储的数据的信息。使用 print(obj)可以直接打印出值。
对象的本质就是:一个内存块,拥有特定的值,支持特定类型的相关操作.
变量也成为:对象的引用。因为,变量存储的就是对象的地址。 变量通过地址引用了“对象”。
简单来说,在 Python中,采用的是基于值的内存管理方式,每个值在内存中只有一份存储。如果给多个变量赋相同的值(如数值类型、字符串类型、元组),那么多个变量存储的都是指向这个值的内存地址,即id。也就是说,Python中的变量并没有存储变量的值,而是存储指向这个值的地址或引用。
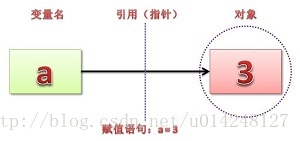
Python 的赋值机制
x = 666
y = x
print(id(x))
print(id(y))
x = x + 1
print(id(x))
print(id(y))
结果如下:
2015992431536
2015992431536
2015992431024
2015992431536
执行以上三句,在 python 中意味着什么, 实际发生了什么?
x = 666会在内存中创建一个整型对象,然后变量x相当于一个标签,贴在此对象上。 y = x 将y也作为这个整型对象的标签,而不是重新在内存中创建一个对象。 x = x+1 将 x 的值加 1,然后在内存中创建另一个整型对象667,将x贴在这个对象上,而不是原来的666 上。
a=3
b=3
c=1
print("a is b结果:"+str(a is b)) #True
print("a is c结果:"+str(a is c)) #False
print("id(a)=%d,id(b)=%d,id(c)=%d"%(id(a),id(b),id(c)))
运行结果如下:
a is b结果:True
a is c结果:False
id(a)=140730432239456,id(b)=140730432239456,id(c)=140730432239392
对象保存在内存空间,这里的’a’和’b’是变量,变量是对象的引用,外部想要使用对象的值,需要通过变量来引用对象。同样的值在内存中只有一份存储,所以’a’和’b’引用的对象是相同的,id(a)=140730432239456=id(b),这个对象的引用数量为2。当某个对象的引用数量为0时,对象会被回收。
变量回收机制
当我们使用 del 删除变量时,我们到底做了什么? 一句话 : 删除贴在对象上的标签,而不是真的删除内存中的对象。 那么我们就无法删除内存中的对象,然后节省内存吗? 可以,但是需要通过 python 的垃圾回收机制。简单来说,就是贴在对象上的标签数量为 0 时,会被 python 自动回收。
可变数据类型与不可变数据类型
- 可变数据类型:列表list和字典dict
- 不可变数据类型:整型int、浮点型float、字符串型string和元组tuple
这里的可变不可变,是指内存中的那块内容(value)是否可以被改变。如果是不可变类型,在对对象本身操作的时候,必须在内存中新申请一块区域(因为老区域不可变)。如果是可变类型,对对象操作的时候,不需要再在其他地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的address会保持不变,但区域会变长或者变短。
也就是说:
- python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象;
- 可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化;对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
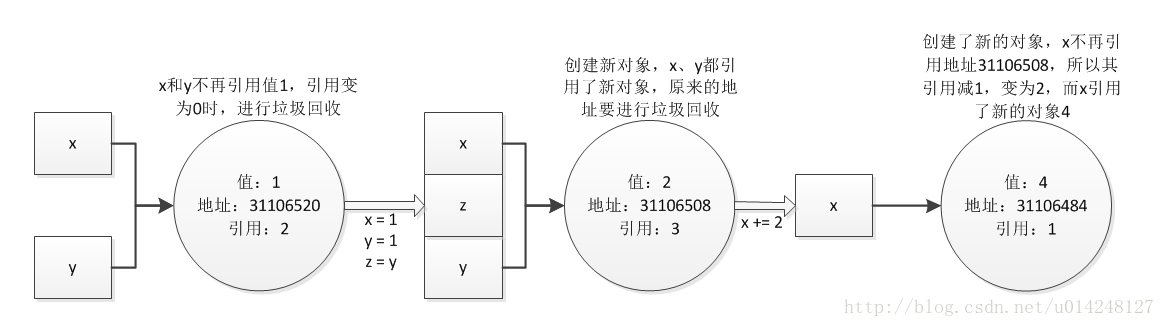
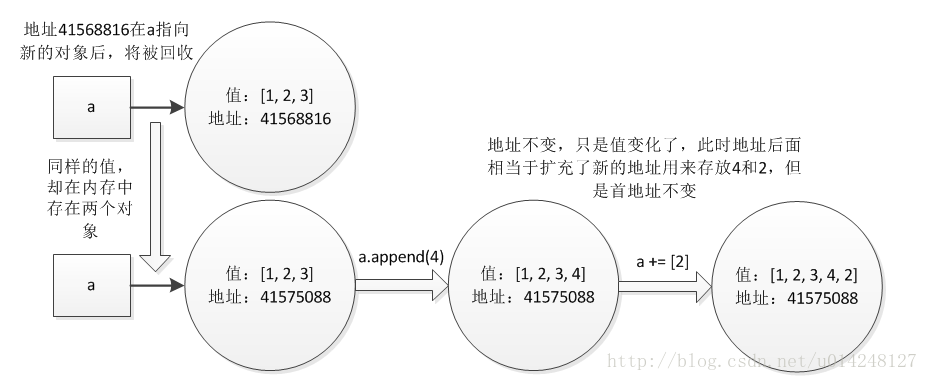
引用传递与值传递
可变对象为引用传递(传址),不可变对象为值传递(传值)。
传值和传址的区别 传值就是传入一个参数的值,传址就是传入一个参数的地址,也就是内存的地址(相当于指针)。他们的区别是如果函数里面对传入的参数重新赋值,函数外的全局变量是否相应改变,用传值传入的参数是不会改变的,用传址传入就会改变。
Python函数参数传递方式:传递对象引用(传值和传址的混合方式),如果是数字,字符串,元组(不可变对象)则传值;如果是列表,字典(可变对象)则传址;
举个例子:
a=1
def f(a):
a+=1
f(a)
print(a)
结果如下:
1
这段代码里面,因为a是数字类型,所以是传值的方式,a的值并不会变,输出为1
a=[1]
def f(a):
a[0]+=1
f(a)
print(a)
结果如下:
[2]
这段代码里面,因为a的类型是列表,所以是传址的形式,$a[0]$的值会改变,输出为$[2]$.
浅拷贝和深拷贝
不止是函数里面,函数外面的引用也同样遵循这个规则:
a=1
b=a
a=2
print(a,b)
a=[1]
b=a
a[0]=2
print(a,b)
输出结果如下:
2 1
[2] [2]
所以在python中,当运行上面的代码时,如果a是字典或者列表的话,程序执行的操作并不是新建一个b变量,然后a的值复制给b,而是新建一个b变量,把b的值指向a,也就是相当于在c语言里面的新建一个指向a的指针。 所以当a的值发生改变时,b的值会相应改变。
如果想要a的值改变时,b的值不改变,就需要用到浅拷贝和深拷贝。
import copy
a=[1,2,3]
b=a
a.append(4)
print(a,b)
a=[1,2,3]
b=copy.copy(a)
a.append(4)
print(a,b)
输出结果如下:
[1, 2, 3, 4] [1, 2, 3, 4]
[1, 2, 3, 4] [1, 2, 3]
这里用了copy来让b与a相等,后面如果修改了a的值,b的值并不会改变。看来copy已经可以实现我们上面的提到的需求了,那么deepcopy又有什么用?
如果我们遇到这种情况,copy就解决不了了:
import copy
a = [1,[1,2],3]
b = copy.copy(a)
a[1].append(3)
print(a,b)
输出结果如下:
[1, [1, 2, 3], 3] [1, [1, 2, 3], 3]
这里a和b的值都改变了,这是因为copy只是复制了一层,如果a里面还有列表,那么b里面的列表也是指向a里面的列表的,所以a里面的列表改变了,b里面的列表也会改变。 这时候就需要用到deepcopy了:
import copy
a = [1,[1,2],3]
b = copy.deepcopy(a)
a[1].append(3)
print(a,b)
输出结果如下:
[1, [1, 2, 3], 3] [1, [1, 2], 3]
这里a的值改变了,b的值没有改变,这是因为deepcopy是递归的复制了所有的值,所以a里面的列表改变了,b里面的列表不会改变。
总结如下: 浅拷贝:浅拷贝中的元素,是对原对象中子对象的引用。此时如果原对象中某一子对象是可变的,改变后会影响拷贝后的对象,存在副作用。一不小心就会触发很大的问题。
深拷贝:深拷贝则会递归的拷贝原对象中的每一个子对象,拷贝之后的对象与原对象没有关系。




