数据来源
数据来源于和鲸社区-2022年中国狭义乘用车分车型销量数据。
查看数据
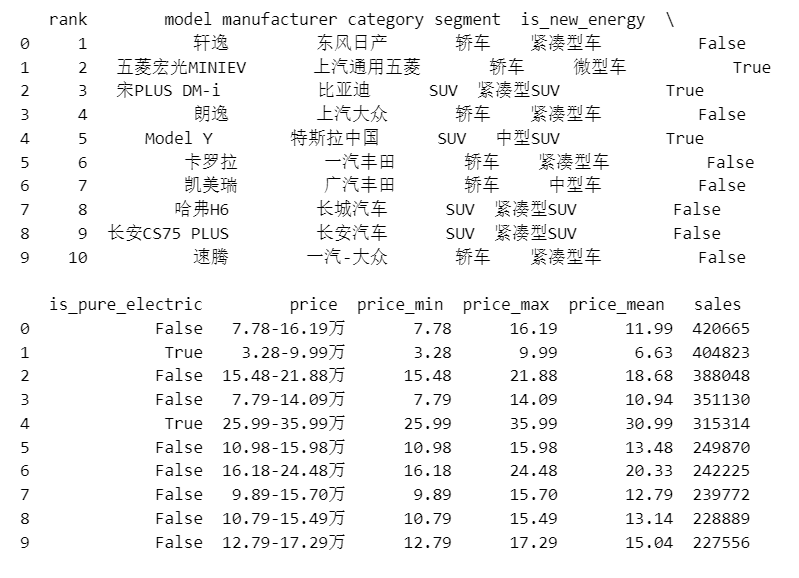
import pandas as pd
df = pd.read_csv('car_sales_2022.csv', names=['rank', 'model', 'manufacturer', 'category', 'segment', 'is_new_energy', 'is_pure_electric', 'price', 'price_min', 'price_max', 'price_mean', 'sales'], header=0)
print(df.head(10))
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
结果如下:
数据清理
print("数据清理前行数:", len(df))
df.drop(df[(df['price_mean'] ==0) | (df['price_mean'].isna())].index, inplace=True)
print("数据清理后行数:", len(df))
结果如下:
数据清理前行数: 612
数据清理后行数: 607
数据查看
按品牌统计车的数量
print(df.groupby('manufacturer')['model'].count().sort_values(ascending=False))
结果如下:
manufacturer
长安汽车 24
长城汽车 23
比亚迪 20
吉利汽车 20
上汽集团 17
..
云度新能源 1
云雀汽车 1
华晨鑫源 1
创维汽车 1
智己汽车 1
Name: model, Length: 106, dtype: int64
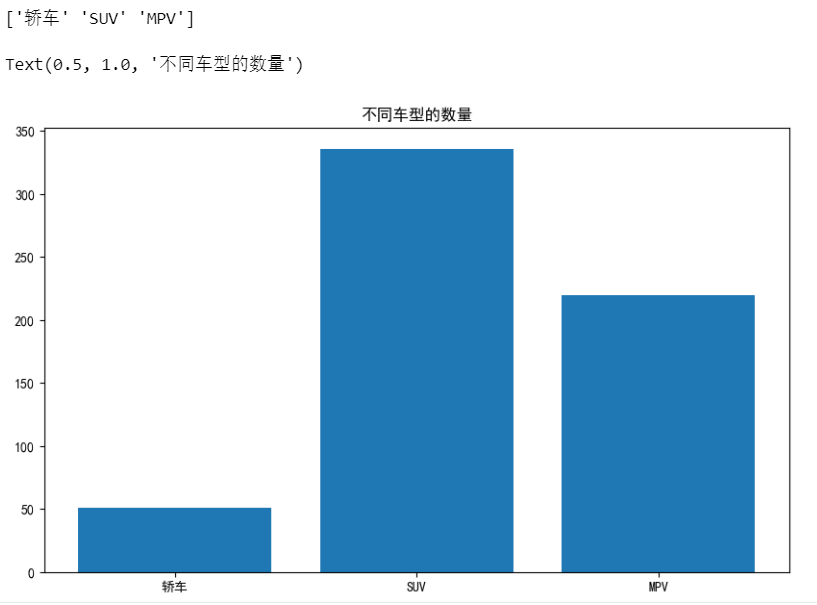
查看汽车类型
# 查看category的取值
print(df['category'].unique())
# 画柱状图,显示category在不同价格区间的车的数量
plt.figure(figsize=(10, 6))
plt.bar(df['category'].unique(), df.groupby('category')['model'].count())
# ['model'] 为列名,['category'] 为行名
plt.title('不同车型的数量')
结果如下:
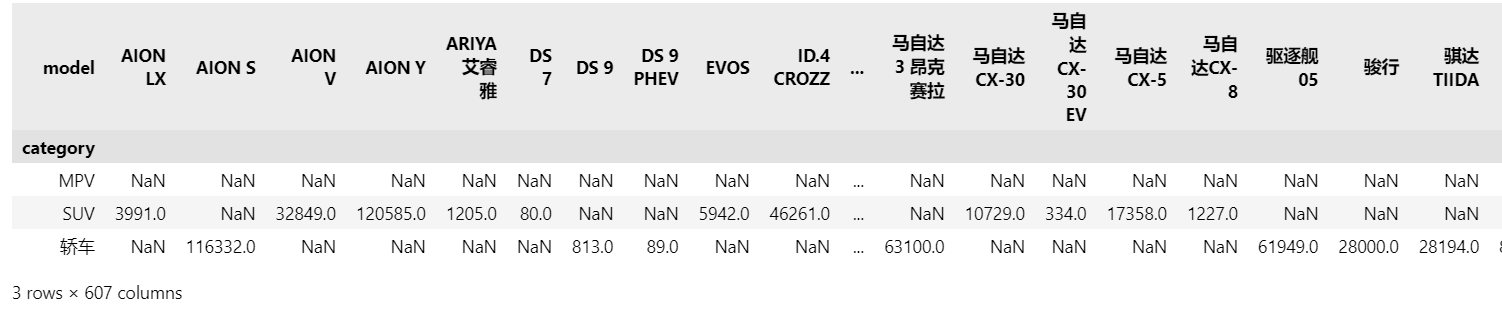
#以category为行名,model为列名,显示销量
pd.pivot_table(df, values='sales', index='category', columns='model')
结果如下:
# 查看segment的取值
print(df['segment'].unique())
# 画饼状图,显示segment的占比
plt.figure(figsize=(6, 6))
plt.pie(df.groupby('segment')['model'].count(), labels=df['segment'].unique(), autopct='%1.1f%%')
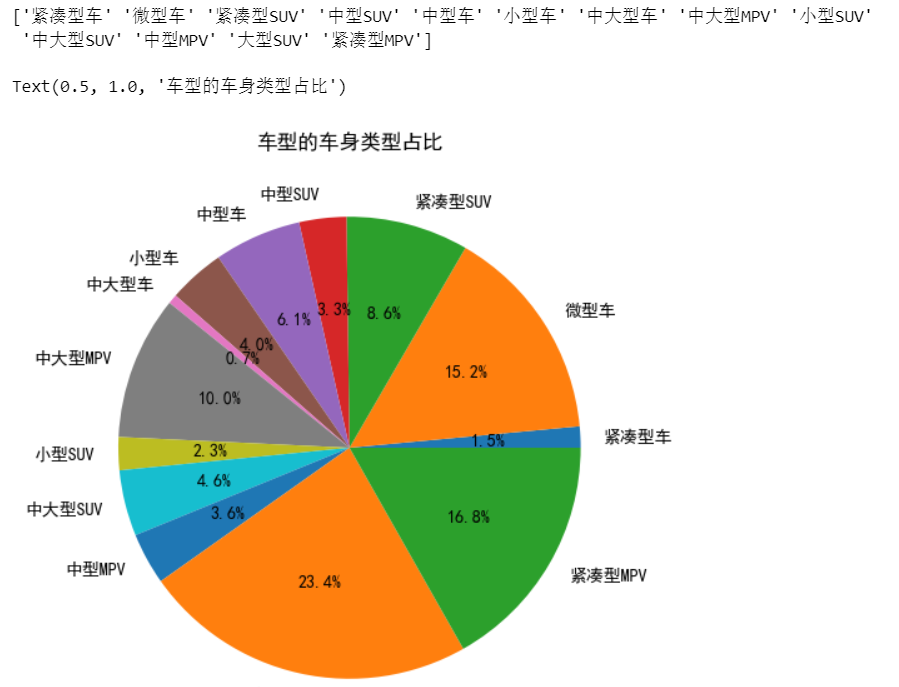
plt.title('车型的车身类型占比')
结果如下:
查看新能源车的数量
# 查看新能源车和非新能源车的销售量
print(df.groupby('is_new_energy')['sales'].sum())
# 查看新能源车和非新能源车的销售量占比
print(df.groupby('is_new_energy')['sales'].sum() / df['sales'].sum())
# 画图
plt.figure(figsize=(6, 6))
plt.pie(df.groupby('is_new_energy')['sales'].sum(), labels=['非新能源车', '新能源车'], autopct='%1.1f%%')
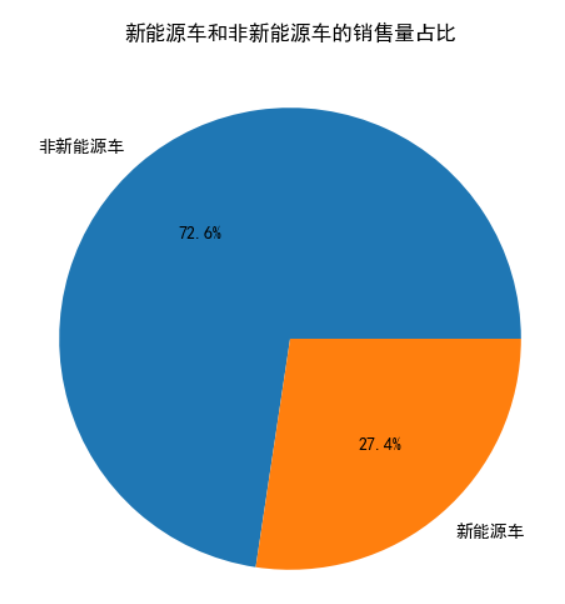
plt.title('新能源车和非新能源车的销售量占比')
plt.show()
结果如下:
is_new_energy
False 14619974
True 5512203
Name: sales, dtype: int64
is_new_energy
False 0.726199
True 0.273801
Name: sales, dtype: float64
按价格区间统计车的品牌和数量
# 按价格区间统计车的品牌和数量
bins = [5, 10, 15, 20, 30, 50, 100]
labels = ['5-10', '10-15', '15-20', '20-30', '30-50', '50-100']
df['price_range'] = pd.cut(df['price_mean'], bins=bins, labels=labels)
print(df.groupby('price_range')['model'].value_counts())
plt.figure(figsize=(10,6))
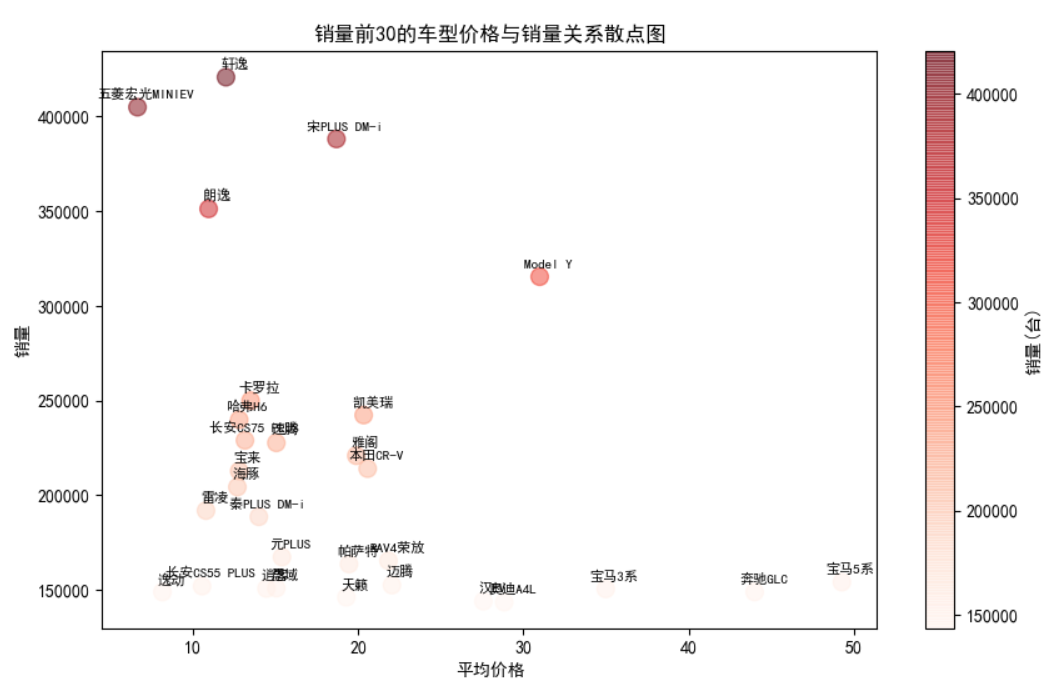
top_30 = df.nlargest(30, 'sales') # 取销量前30的车型
plt.scatter(top_30['price_mean'], top_30['sales'], s=100, alpha=0.5, c=top_30['sales'], cmap='Reds')
plt.colorbar(label='销量(台)')
for i, txt in enumerate(top_30['model']):
#plt.annotate(txt, (top_30['price_mean'].iloc[i], top_30['sales'].iloc[i]))
plt.annotate(txt, (top_30['price_mean'].iloc[i], top_30['sales'].iloc[i]), xytext=(5, 5), textcoords='offset points', fontsize=8, ha='center')
# 标注车型 enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
# 同时列出数据和数据下标,一般用在 for 循环当中。
# iloc[] 通过行号来获取行数据
plt.xlabel('平均价格')
plt.ylabel('销量')
plt.title('销量前30的车型价格与销量关系散点图')
plt.show()
结果如下:
price_range model
5-10 VGV U70 1
VGV U70Pro 1
YARiS L 致享 1
YARiS L 致炫 1
YOUNG光小新 1
..
50-100 红旗H9 1
英菲尼迪QX60 1
蔚来ES7 1
蔚来ES8 1
飞行家 1
Name: model, Length: 597, dtype: int64
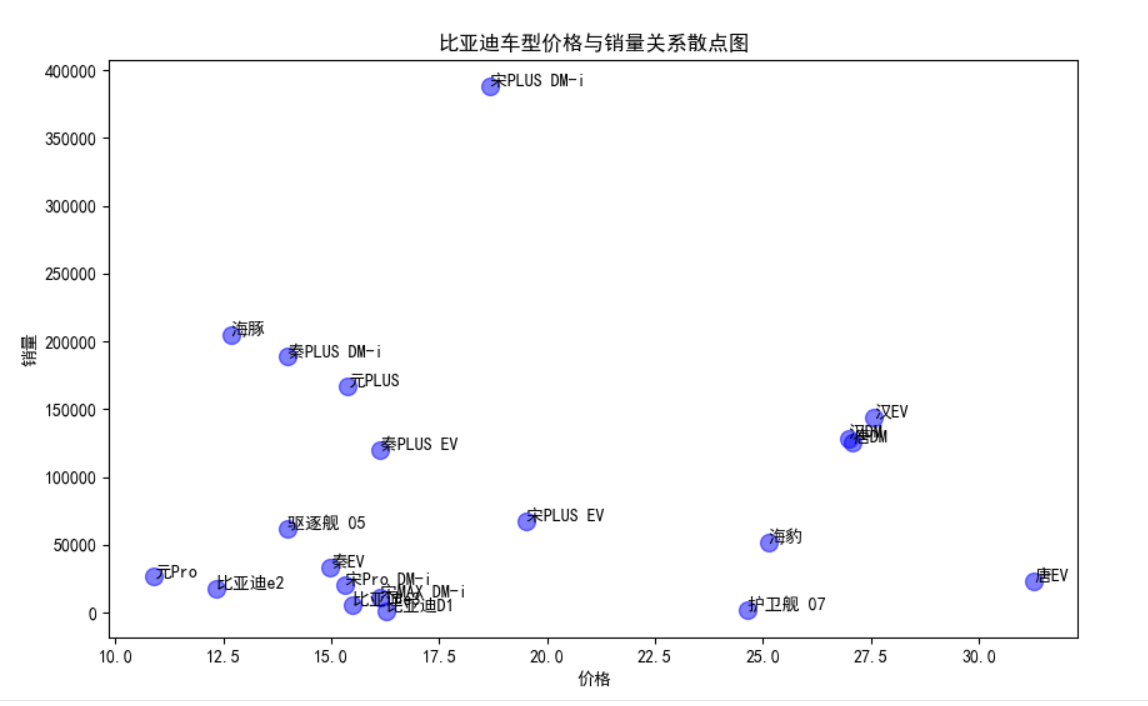
查看比亚迪销售情况
print(df[df['manufacturer']=='比亚迪'][['model', 'price_mean', 'sales']])
plt.figure(figsize=(10,6))
df_byd = df[df['manufacturer']=='比亚迪']
plt.scatter(df_byd['price_mean'], df_byd['sales'], s=100, alpha=0.5, c='blue')
for i, txt in enumerate(df_byd['model']):
plt.annotate(txt, (df_byd['price_mean'].iloc[i], df_byd['sales'].iloc[i]))
plt.xlabel('价格')
plt.ylabel('销量')
plt.title('比亚迪车型价格与销量关系散点图')
plt.show()
结果如下:
model price_mean sales
2 宋PLUS DM-i 18.68 388048
13 海豚 12.68 204226
15 秦PLUS DM-i 13.98 188522
16 元PLUS 15.38 167220
28 汉EV 27.58 143895
35 汉DM 26.98 128524
39 唐DM 27.08 125368
47 秦PLUS EV 16.13 119755
96 宋PLUS EV 19.53 66935
102 驱逐舰 05 13.98 61949
121 海豹 25.13 51200
160 秦EV 14.98 33665
181 元Pro 10.88 26313
199 唐EV 31.28 23217
226 宋Pro DM-i 15.33 20323
242 比亚迪e2 12.33 17790
308 宋MAX DM-i 16.13 11037
385 比亚迪e3 15.48 5726
488 护卫舰 07 24.63 1805
529 比亚迪D1 16.28 994