
1. 随机生成一个随机的string

结果如下:(根据和github里面搜出来的代码块基本上是一样的,挺简洁的)
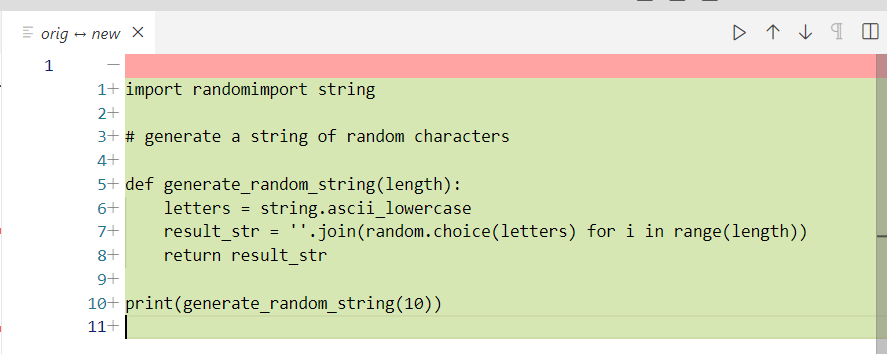
调整一下就可以直接使用
import random
import string
# generate a string of random characters
def generate_random_string(length):
letters = string.ascii_lowercase
result_str = ''.join(random.choice(letters) for i in range(length))
return result_str
print(generate_random_string(10))
运行代码,结果如下:

2. 对字符串进行切片
首先,我大概想了下以后可能要处理的文件的文件名,可能是这个格式,最开始是设备的安装日期,然后是地点,机组号码,传感器编号,最后是这个装置的布防期间,大概是这样滴。
string1= '2015-01-01-内蒙-机组304-308传感器-测试期间-from-2016-03-04-to-2018-05-07'
接着,我希望codecursor帮我写代码切割字符串:
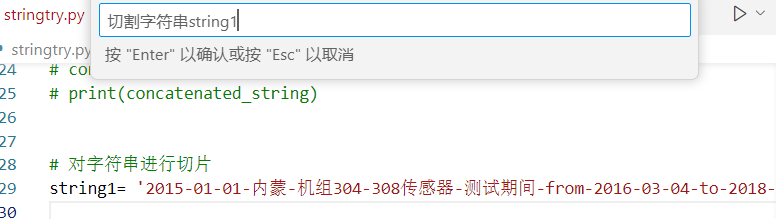
得到的建议代码如下:
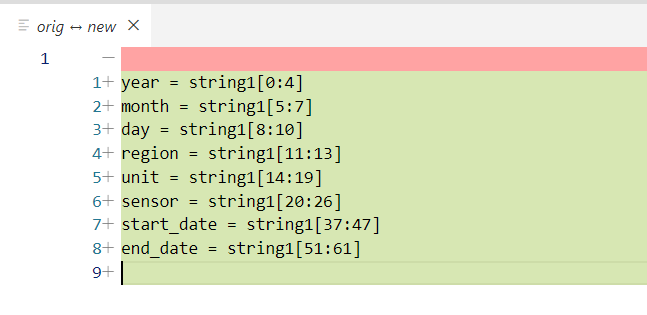
print一下结果发现是可以直接用的,已经切割出了符合我们预期的substring:

string1= '2015-01-01-内蒙-机组304-308传感器-测试期间-from-2016-03-04-to-2018-05-07'
year = string1[0:4]
month = string1[5:7]
day = string1[8:10]
region = string1[11:13]
unit = string1[14:19]
sensor = string1[20:26]
start_date = string1[37:47]
end_date = string1[51:61]
print(year, month, day, region, unit, sensor,start_date, end_date)
但是我试了下,在大部分情况下,他提取的substring都有问题,最好是print出来看看,然后再调整一下。
3. 批量提取字符串中的信息
我们距离目标很近了,有时候我们期待我们可以对多个文件进行操作,那么这时候我们可能需要构造一个提取信息的函数帮助我们完成这个任务。
首先,我们生成一系列和string1格式相同的字符串,看看codecursor能不能帮我们做到这一点:

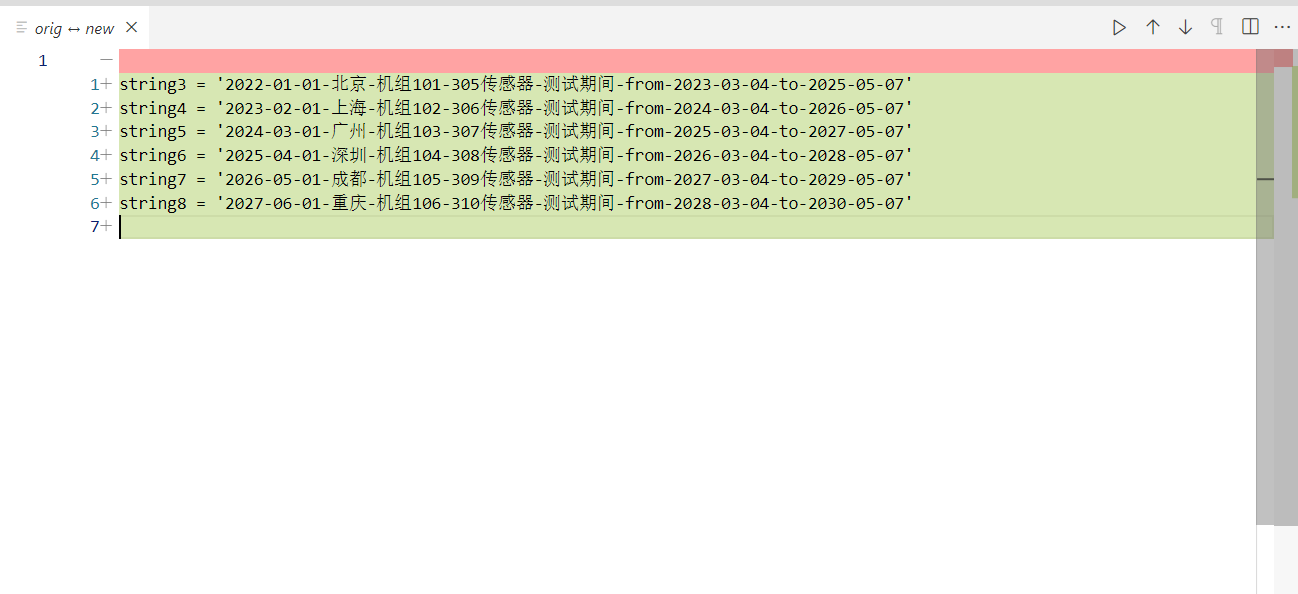
神了,它居然这都可以做到。
然后,我们构造提取信息的函数,在这里就不演示codecursor的操作了,直接上它帮助我们写好的代码:
# 生成新的字符串
string3 = '2022-01-01-北京-机组101-305传感器-测试期间-from-2023-03-04-to-2025-05-07'
string4 = '2023-02-01-上海-机组102-306传感器-测试期间-from-2024-03-04-to-2026-05-07'
string5 = '2024-03-01-广州-机组103-307传感器-测试期间-from-2025-03-04-to-2027-05-07'
string6 = '2025-04-01-深圳-机组104-308传感器-测试期间-from-2026-03-04-to-2028-05-07'
string7 = '2026-05-01-成都-机组105-309传感器-测试期间-from-2027-03-04-to-2029-05-07'
string8 = '2027-06-01-重庆-机组106-310传感器-测试期间-from-2028-03-04-to-2030-05-07'
# 构造提取信息的函数
def extract_info(string):
year = string[0:4]
month = string[5:7]
day = string[8:10]
region = string[11:13]
unit = string[14:19]
sensor = string[20:26]
start_date = string[37:47]
end_date = string[51:61]
return year, month, day, region, unit, sensor, start_date, end_date
year, month, day, region, unit, sensor, start_date, end_date = extract_info(string3)
print(year, month, day, region, unit, sensor, start_date, end_date)
运行结果如下:

4.批量保存提取的信息
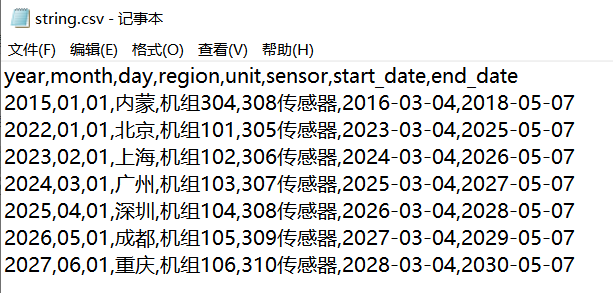
还是跳过操作步骤,给出codecursor给的代码:
# 将列表转换为表格
string_list = [string1,string3, string4, string5, string6, string7, string8]
table = []
for string in string_list:
info = extract_info(string)
table.append(info)
print(table)
# 将表格转换为DataFrame,并保存为csv文件
import pandas as pd
df = pd.DataFrame(table, columns=['year', 'month', 'day', 'region', 'unit', 'sensor', 'start_date', 'end_date'])
df.to_csv('string.csv', index=False)
运行代码,结果如下:
5.其他探索
生成新的字符串那一步我不太满意,这次我希望他可以帮助我自动生成和string1一样格式的字符串,它给出的代码是这样的:
import random
def generate_random_string():
year = str(random.randint(2022, 2027))
month = str(random.randint(1, 12)).zfill(2)
day = str(random.randint(1, 28)).zfill(2)
region = random.choice(['北京', '上海', '广州', '深圳', '成都', '重庆'])
unit = '机组' + str(random.randint(101, 106))
sensor = str(random.randint(305, 310)) + '传感器'
start_year = str(random.randint(int(year)+1, 2029)) # int()方法用于将字符串转换为整数, int(year)+1表示将字符串转换为整数后加1
start_month = str(random.randint(1, 12)).zfill(2) # zfill()方法用于将字符串的长度补全为指定的长度,不足的部分用0填充
start_day = str(random.randint(1, 28)).zfill(2)
end_year = str(random.randint(int(start_year)+1, 2030))
end_month = str(random.randint(1, 12)).zfill(2)
end_day = str(random.randint(1, 28)).zfill(2)
string = year + '-' + month + '-' + day + '-' + region + '-' + unit + '-' + sensor + '-测试期间-from-' + start_year + '-' + start_month + '-' + start_day + '-to-' + end_year + '-' + end_month + '-' + end_day
return string
string_list = []
for i in range(20):
string_list.append(generate_random_string())
print(string_list)
运行结果如下:





