
1. 数据来源
kaggle-Wind Speed Prediction Dataset
气象学家们面临着高精度和可靠的风速预测的挑战。由于对流暴风引起的严重风灾造成了相当大的损害(如大规模的森林破坏、停电、建筑物/房屋损坏等),因此风速预测是获取先进的严重天气警报的重要任务。本数据集包含了收集不同天气变量(如温度和降水)的气象传感器的响应。
该数据集包含了6574个实例的日均响应,来自于一个包含5个天气变量传感器阵列的气象站。该设备位于一个相对空旷的区域内,海拔21米。数据记录时间为1961年1月至1978年12月(17年)。提供了地面真实的日均降水量、最高和最低温度以及草地最低温度。
属性信息
- DATE (YYYY-MM-DD)
- WIND: Average wind speed [knots]
- IND: First indicator value
- RAIN: Precipitation Amount (mm)
- IND.1: Second indicator value
- T.MAX: Maximum Temperature (°C)
- IND.2: Third indicator value
- T.MIN: Minimum Temperature (°C)
- T.MIN.G: 09utc Grass Minimum Temperature (°C)
2. 数据预处理
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk('./input'):
for filename in filenames:
print(os.path.join(dirname, filename))
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
import datetime
from sklearn.metrics import mean_absolute_error
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
df=pd.read_csv('./input/wind_dataset.csv')
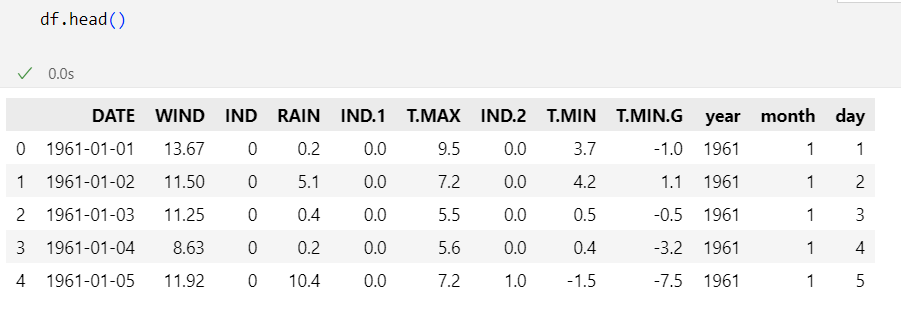
df.head()
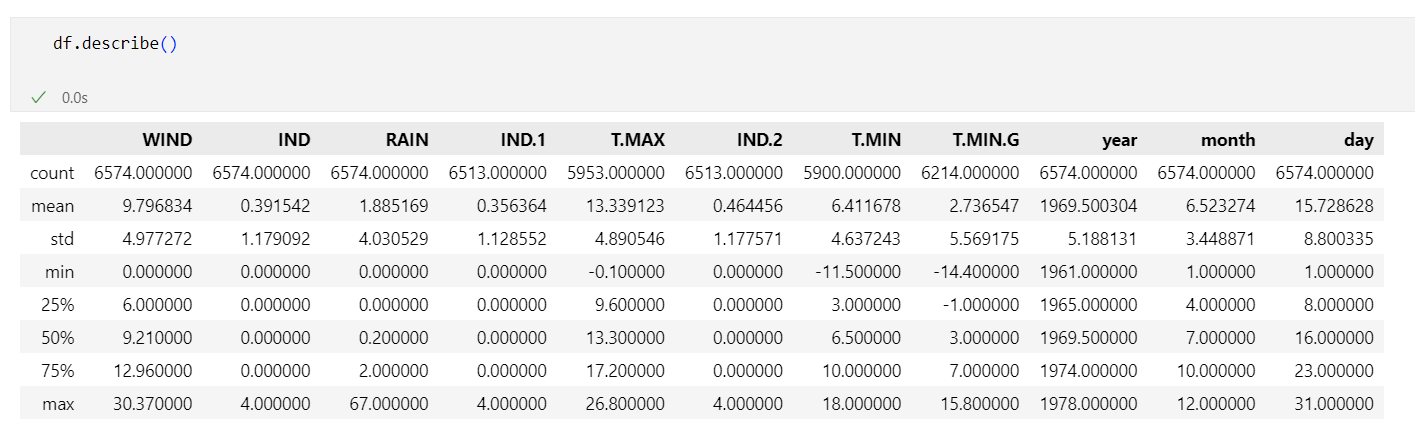
df.info()
df.shape
# 对日期进行处理
df['DATE']=pd.to_datetime(df['DATE'])
# extract year, month and day from DATE
df['year']=df['DATE'].dt.year
df['month']=df['DATE'].dt.month
df['day']=df['DATE'].dt.day
输出结果如下:
Python 3.8.3 (default, Jul 2 2020, 17:30:36) [MSC v.1916 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.34.0 -- An enhanced Interactive Python. Type '?' for help.
./input\wind_dataset.csv
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6574 entries, 0 to 6573
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 DATE 6574 non-null object
1 WIND 6574 non-null float64
2 IND 6574 non-null int64
3 RAIN 6574 non-null float64
4 IND.1 6513 non-null float64
5 T.MAX 5953 non-null float64
6 IND.2 6513 non-null float64
7 T.MIN 5900 non-null float64
8 T.MIN.G 6214 non-null float64
dtypes: float64(7), int64(1), object(1)
memory usage: 462.4+ KB
DATE WIND IND RAIN IND.1 T.MAX IND.2 T.MIN T.MIN.G year month day
0 1961-01-01 13.67 0 0.2 0.0 9.5 0.0 3.7 -1.0 1961 1 1
1 1961-01-02 11.50 0 5.1 0.0 7.2 0.0 4.2 1.1 1961 1 2
2 1961-01-03 11.25 0 0.4 0.0 5.5 0.0 0.5 -0.5 1961 1 3
3 1961-01-04 8.63 0 0.2 0.0 5.6 0.0 0.4 -3.2 1961 1 4
4 1961-01-05 11.92 0 10.4 0.0 7.2 1.0 -1.5 -7.5 1961 1 5
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6574 entries, 0 to 6573
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 DATE 6574 non-null datetime64[ns]
1 WIND 6574 non-null float64
2 IND 6574 non-null int64
3 RAIN 6574 non-null float64
4 IND.1 6513 non-null float64
5 T.MAX 5953 non-null float64
6 IND.2 6513 non-null float64
7 T.MIN 5900 non-null float64
8 T.MIN.G 6214 non-null float64
9 year 6574 non-null int64
10 month 6574 non-null int64
11 day 6574 non-null int64
dtypes: datetime64[ns](1), float64(7), int64(4)
memory usage: 616.4 KB
查看数据是否有缺失值:
df.isnull().sum()
结果如下:
DATE 0
WIND 0
IND 0
RAIN 0
IND.1 61
T.MAX 621
IND.2 61
T.MIN 674
T.MIN.G 360
year 0
month 0
day 0
dtype: int64
# 用backfill (bfill)填充null
df = df.fillna(method='bfill')
然后再使用isnull()函数检查是否还有缺失值。
也可以用每一列出现最多的值来填充缺失值:
colu = ["IND.1","T.MAX" ,"IND.2" ,"T.MIN" ,"T.MIN.G" ]
for i in colu:
print(i)
print(df[i].mode()) # mode() 函数返回众数
df[i].fillna(df[i].mode()[0],inplace=True) # inplace=True表示在原数据上修改
3. 数据可视化
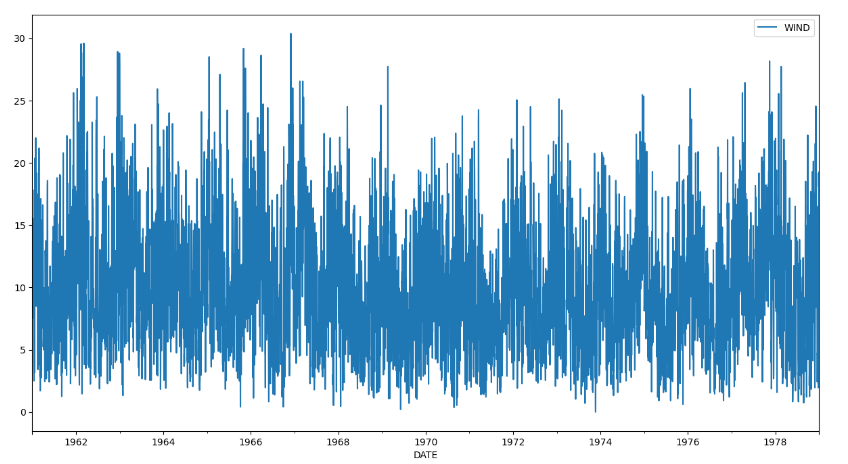
风速随着时间的变化情况:
df.plot(x='DATE',y='WIND',figsize=(15,8))
输出结果如下:
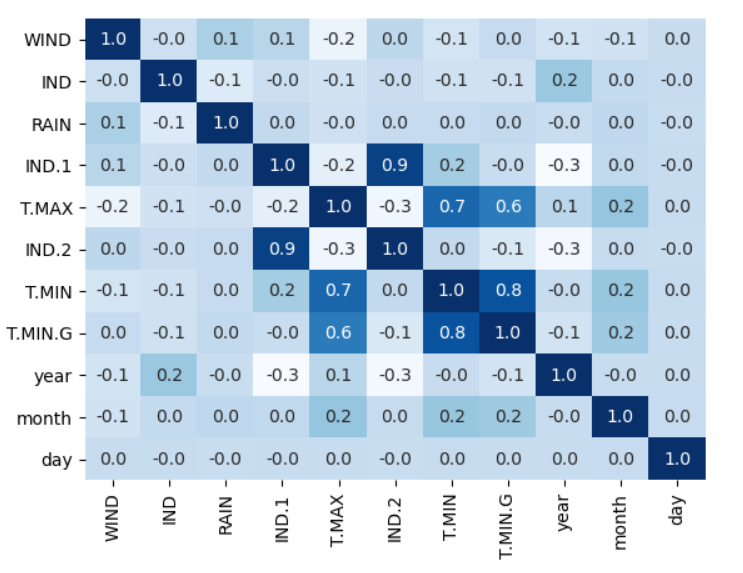
各个特征值之间的相互关系:
sns.heatmap(df.corr(),annot=True, cbar=False, cmap='Blues', fmt='.1f')
# cbar=False表示不显示颜色条, cmap='Blues'表示颜色为蓝色, fmt='.1f'表示保留一位小数,annot=True表示显示相关系数
输出结果如下:
画出风速,降雨量,最高温度,最低温度的箱线图:
fig, axes = plt.subplots(2, 2, figsize=(15, 8))
sns.boxplot(df['WIND'],ax=axes[0,0]) # Boxplot:'Wind'
# axes[0,0].set_title('Wind') # title
sns.boxplot(df['RAIN'],ax=axes[0,1]) # Boxplot:'Rain'
# axes[0,1].set_title('Rain') # title
sns.boxplot(df['T.MAX'],ax=axes[1,0]) # Boxplot:'Max Temperature'
# axes[1,0].set_title('Max Temperature') # title
sns.boxplot(df['T.MIN'],ax=axes[1,1]) # Boxplot:'Min Temperature'
# axes[1,1].set_title('Min Temperature') # title
结果如下:
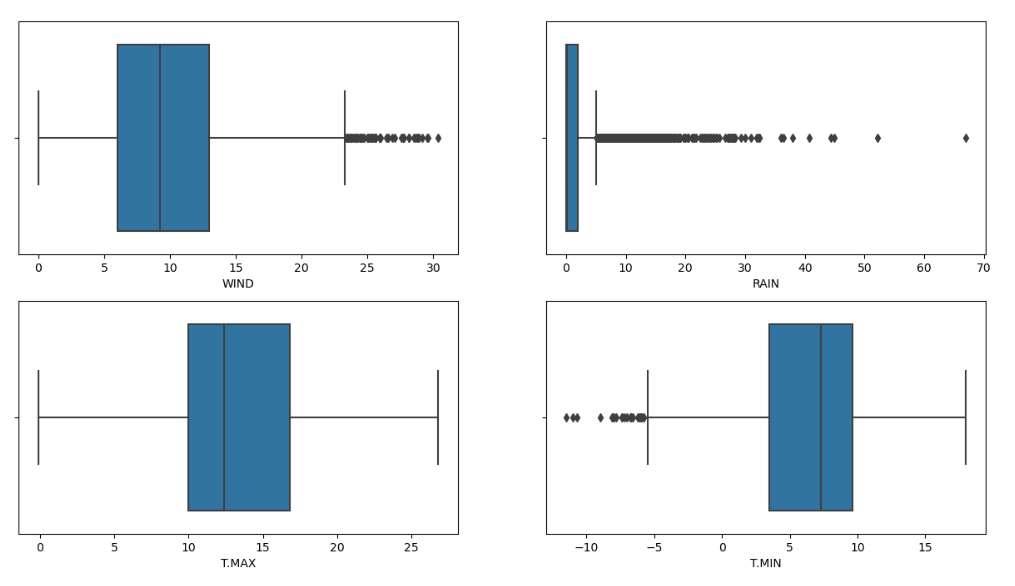
可以发现,风速平均值在9knots左右,降雨量有很多高的异常值,最高温度平均值在12°左右,最低温度平均值在8°左右,最低温度有一些异常的低值。
画出所有变量的时间序列图:
df = df.set_index('DATE')
df.head()
from matplotlib import pyplot
# load dataset
values = df.values
# specify columns to plot
groups = [0, 1, 2, 3,4, 5, 6, 7]
i = 1
# plot each column
pyplot.figure(figsize=(15,15))
for group in groups:
pyplot.subplot(len(groups), 1, i)
pyplot.plot(values[:, group])
pyplot.title(df.columns[group], y=0.5, loc='right')
i += 1
pyplot.show()
结果如下:
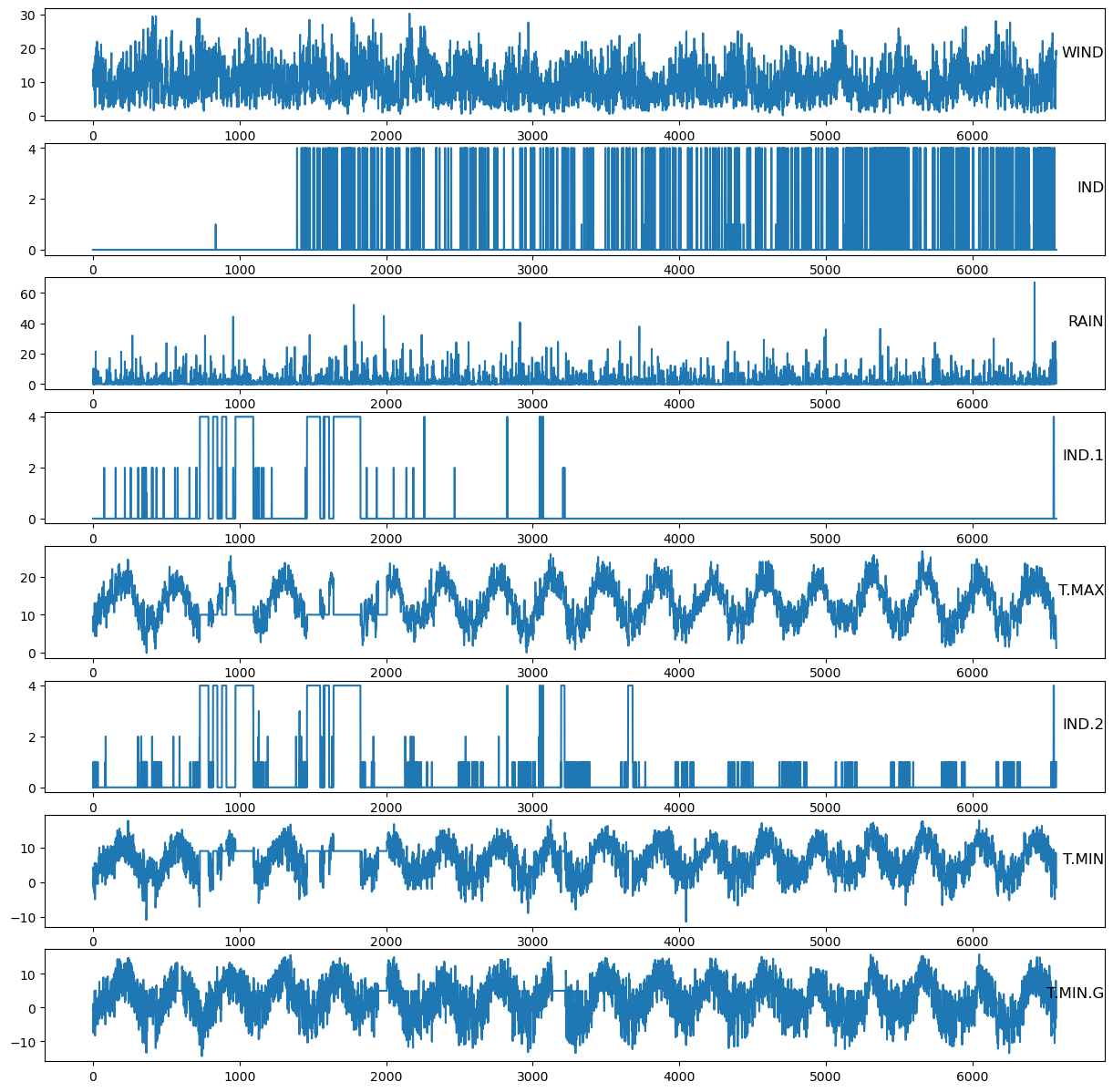
4. 变量之间的关系
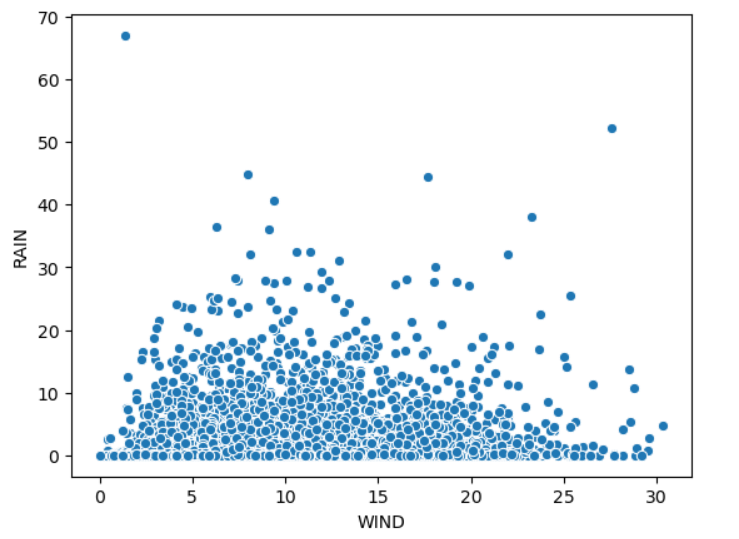
4.1 风速与降雨量的关系
sns.scatterplot(x='WIND',y='RAIN',data=df)
输出结果如下:
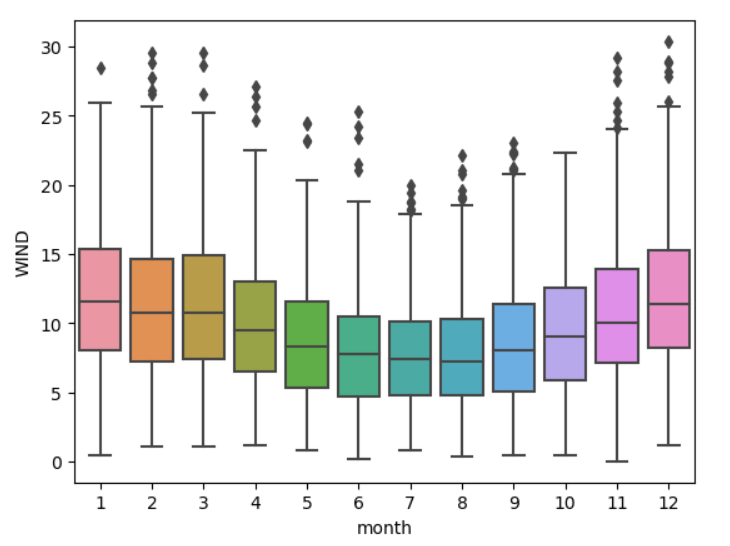
4.2 降雨量月度变化
sns.boxplot(x=df['month'] ,y=df["WIND"])
输出结果如下:
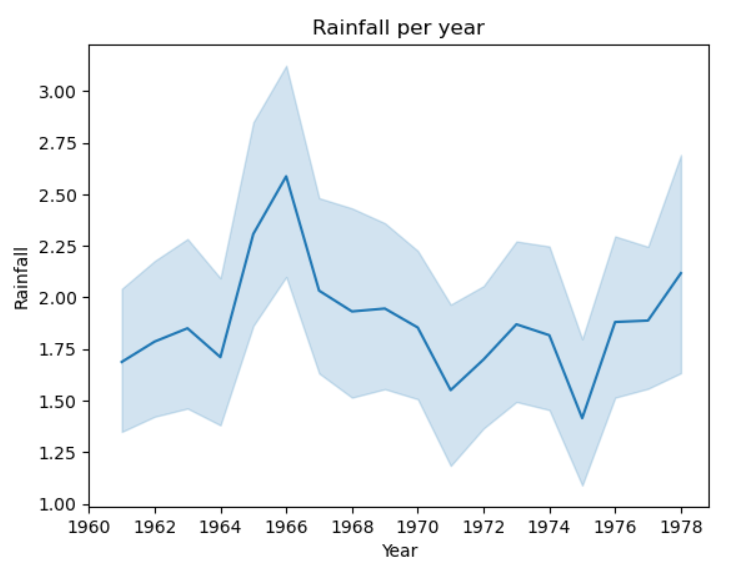
4.3 降雨量年度变化折线图
sns.lineplot(x=df['year'] ,y=df["RAIN"])
# sns.lineplot(x=df['year'] ,y=df["RAIN"],ci=None)
# 不要误差线,ci表示置信区间
# 横坐标为年份,纵坐标为降雨量
plt.title('Rainfall per year')
plt.xlabel('Year')
plt.ylabel('Rainfall')
# 设置横坐标取值
plt.xticks(np.arange(1960,1980,2))
输出结果如下:
5. 时间序列预测
5.1 LSTM
LSTM是指长短期记忆网络(Long Short-Term Memory networks),是一种特殊的RNN,能够学习长期依赖关系。
5.2 训练
这个还不是很懂,还需要时间消化消化。
# Train – Test Split
# 去掉年月日的列
df = df.drop(['year','month','day'],axis=1)
train_df,test_df = df[1:4601], df[4601:]
# 缩放
train = train_df
scalers={}
for i in train_df.columns:
scaler = MinMaxScaler(feature_range=(-1,1)) # MinMaxScaler缩放到[-1,1]之间
s_s = scaler.fit_transform(train[i].values.reshape(-1,1))
s_s=np.reshape(s_s,len(s_s))
scalers['scaler_'+ i] = scaler
train[i]=s_s
test = test_df
for i in train_df.columns:
scaler = scalers['scaler_'+i]
s_s = scaler.transform(test[i].values.reshape(-1,1))
s_s=np.reshape(s_s,len(s_s))
scalers['scaler_'+i] = scaler
test[i]=s_s
# 使用滑动窗口方法将我们的序列转换为输入过去观测值的样本,
# 并输出未来观测值,以使用监督式学习算法。
def split_series(series, n_past, n_future):
X, y = list(), list()
for window_start in range(len(series)):
past_end = window_start + n_past
future_end = past_end + n_future
if future_end > len(series):
break
past, future = series[window_start:past_end, :], series[past_end:future_end, :]
X.append(past)
y.append(future)
return np.array(X), np.array(y)
# 假设根据过去10天的观测,我们需要预测未来5天的观测。
n_past = 10
n_future = 5
n_features = 8
# 转换数据成为samples
X_train, y_train = split_series(train.values,n_past, n_future)
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1],n_features))
y_train = y_train.reshape((y_train.shape[0], y_train.shape[1], n_features))
X_test, y_test = split_series(test.values,n_past, n_future)
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1],n_features))
y_test = y_test.reshape((y_test.shape[0], y_test.shape[1], n_features))
# 建模
## E1D1
encoder_inputs = tf.keras.layers.Input(shape=(n_past, n_features))
encoder_l1 = tf.keras.layers.LSTM(100, return_state=True)
encoder_outputs1 = encoder_l1(encoder_inputs)
encoder_states1 = encoder_outputs1[1:]
decoder_inputs = tf.keras.layers.RepeatVector(n_future)(encoder_outputs1[0])
decoder_l1 = tf.keras.layers.LSTM(100, return_sequences=True)(decoder_inputs,initial_state = encoder_states1)
decoder_outputs1 = tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(n_features))(decoder_l1)
model_e1d1 = tf.keras.models.Model(encoder_inputs,decoder_outputs1)
model_e1d1.summary()
## E2D2
## 具有两个编码层和两个解码层的序列模型
encoder_inputs = tf.keras.layers.Input(shape=(n_past, n_features))
encoder_l1 = tf.keras.layers.LSTM(100,return_sequences = True, return_state=True)
encoder_outputs1 = encoder_l1(encoder_inputs)
encoder_states1 = encoder_outputs1[1:]
encoder_l2 = tf.keras.layers.LSTM(100, return_state=True)
encoder_outputs2 = encoder_l2(encoder_outputs1[0])
encoder_states2 = encoder_outputs2[1:]
decoder_inputs = tf.keras.layers.RepeatVector(n_future)(encoder_outputs2[0])
decoder_l1 = tf.keras.layers.LSTM(100, return_sequences=True)(decoder_inputs,initial_state = encoder_states1)
decoder_l2 = tf.keras.layers.LSTM(100, return_sequences=True)(decoder_l1,initial_state = encoder_states2)
decoder_outputs2 = tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(n_features))(decoder_l2)
model_e2d2 = tf.keras.models.Model(encoder_inputs,decoder_outputs2)
model_e2d2.summary()
# 训练模型
reduce_lr = tf.keras.callbacks.LearningRateScheduler(lambda x: 1e-3 * 0.90 ** x)
model_e1d1.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.Huber())
history_e1d1=model_e1d1.fit(X_train,y_train,epochs=25,validation_data=(X_test,y_test),batch_size=32,verbose=0,callbacks=[reduce_lr])
model_e2d2.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.Huber())
history_e2d2=model_e2d2.fit(X_train,y_train,epochs=25,validation_data=(X_test,y_test),batch_size=32,verbose=0,callbacks=[reduce_lr])
# 得到预测值
pred_e1d1=model_e1d1.predict(X_test)
pred_e2d2=model_e2d2.predict(X_test)
# 反缩放
for index,i in enumerate(train_df.columns):
scaler = scalers['scaler_'+i]
pred_e1d1[:,:,index]=scaler.inverse_transform(pred_e1d1[:,:,index])
pred_e2d2[:,:,index]=scaler.inverse_transform(pred_e2d2[:,:,index])
y_train[:,:,index]=scaler.inverse_transform(y_train[:,:,index])
y_test[:,:,index]=scaler.inverse_transform(y_test[:,:,index])
# check error
from sklearn.metrics import mean_absolute_error
for index,i in enumerate(train_df.columns):
print(i)
for j in range(1,6):
print("Day ",j,":")
print("MAE-E1D1 : ",mean_absolute_error(y_test[:,j-1,index],pred_e1d1[:,j-1,index]),end=", ")
print("MAE-E2D2 : ",mean_absolute_error(y_test[:,j-1,index],pred_e2d2[:,j-1,index]))
print()
print()
# 评估模型
def evaluate_model(y_true,y_pred):
mae = np.mean(np.abs(y_true-y_pred))
mape = np.mean(np.abs((y_true-y_pred)/y_true))
rmse = np.sqrt(np.mean((y_true-y_pred)**2))
return mae,mape,rmse
# MAE表示预测值与真实值之间的平均绝对误差,MAPE表示预测值与真实值之间的平均绝对百分比误差,RMSE表示预测值与真实值之间的均方根误差。
mae_e1d1,mape_e1d1,rmse_e1d1=evaluate_model(y_test,pred_e1d1)
print("MAE-E1D1 : ",mae_e1d1)
print("MAPE-E1D1 : ",mape_e1d1)
print("RMSE-E1D1 : ",rmse_e1d1)
mae_e2d2,mape_e2d2,rmse_e2d2=evaluate_model(y_test,pred_e2d2)
print("MAE-E2D2 : ",mae_e2d2)
print("MAPE-E2D2 : ",mape_e2d2)
print("RMSE-E2D2 : ",rmse_e2d2)
输出结果如下:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 10, 8)] 0 []
lstm (LSTM) [(None, 100), 43600 ['input_1[0][0]']
(None, 100),
(None, 100)]
repeat_vector (RepeatVector) (None, 5, 100) 0 ['lstm[0][0]']
lstm_1 (LSTM) (None, 5, 100) 80400 ['repeat_vector[0][0]',
'lstm[0][1]',
'lstm[0][2]']
time_distributed (TimeDistribu (None, 5, 8) 808 ['lstm_1[0][0]']
ted)
==================================================================================================
Total params: 124,808
Trainable params: 124,808
Non-trainable params: 0
__________________________________________________________________________________________________
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 10, 8)] 0 []
lstm_2 (LSTM) [(None, 10, 100), 43600 ['input_2[0][0]']
(None, 100),
(None, 100)]
lstm_3 (LSTM) [(None, 100), 80400 ['lstm_2[0][0]']
(None, 100),
(None, 100)]
repeat_vector_1 (RepeatVector) (None, 5, 100) 0 ['lstm_3[0][0]']
lstm_4 (LSTM) (None, 5, 100) 80400 ['repeat_vector_1[0][0]',
'lstm_2[0][1]',
'lstm_2[0][2]']
lstm_5 (LSTM) (None, 5, 100) 80400 ['lstm_4[0][0]',
'lstm_3[0][1]',
'lstm_3[0][2]']
time_distributed_1 (TimeDistri (None, 5, 8) 808 ['lstm_5[0][0]']
buted)
==================================================================================================
Total params: 285,608
Trainable params: 285,608
Non-trainable params: 0
__________________________________________________________________________________________________
62/62 [==============================] - 1s 4ms/step
62/62 [==============================] - 2s 7ms/step
WIND
Day 1 :
MAE-E1D1 : 0.2030982378059999, MAE-E2D2 : 0.20359981017286832
Day 2 :
MAE-E1D1 : 0.23322182065839472, MAE-E2D2 : 0.2322014858929193
Day 3 :
MAE-E1D1 : 0.240528954285563, MAE-E2D2 : 0.2399887921500838
Day 4 :
MAE-E1D1 : 0.24262299357094172, MAE-E2D2 : 0.24300205558516846
Day 5 :
MAE-E1D1 : 0.24477795444422737, MAE-E2D2 : 0.24521872620795385
IND
Day 1 :
MAE-E1D1 : 0.8192329511403916, MAE-E2D2 : 0.8078464830086023
Day 2 :
MAE-E1D1 : 0.8205593273674974, MAE-E2D2 : 0.809087825709913
Day 3 :
MAE-E1D1 : 0.8095268123061028, MAE-E2D2 : 0.7957327934233981
Day 4 :
MAE-E1D1 : 0.8005428497982366, MAE-E2D2 : 0.7832877624393909
Day 5 :
MAE-E1D1 : 0.7966770311592184, MAE-E2D2 : 0.7773387461307403
RAIN
Day 1 :
MAE-E1D1 : 0.09180004186695194, MAE-E2D2 : 0.09083399148450579
Day 2 :
MAE-E1D1 : 0.0924991551961152, MAE-E2D2 : 0.09287003019686486
Day 3 :
MAE-E1D1 : 0.09169342586566709, MAE-E2D2 : 0.09171447431362073
Day 4 :
MAE-E1D1 : 0.0918647467209567, MAE-E2D2 : 0.09168521043800822
Day 5 :
MAE-E1D1 : 0.09274870878211129, MAE-E2D2 : 0.09302511114610458
IND.1
Day 1 :
MAE-E1D1 : 0.019823942188936086, MAE-E2D2 : 0.022393431063815607
Day 2 :
MAE-E1D1 : 0.019041566405447238, MAE-E2D2 : 0.021436605376209027
Day 3 :
MAE-E1D1 : 0.020100323505216622, MAE-E2D2 : 0.02054175316161681
Day 4 :
MAE-E1D1 : 0.02028246833968978, MAE-E2D2 : 0.019219360192129963
Day 5 :
MAE-E1D1 : 0.020312563383560998, MAE-E2D2 : 0.01931783006226548
T.MAX
Day 1 :
MAE-E1D1 : 0.1232421095326075, MAE-E2D2 : 0.12522745991132936
Day 2 :
MAE-E1D1 : 0.1474737389383158, MAE-E2D2 : 0.1490627993920697
Day 3 :
MAE-E1D1 : 0.15721180848764904, MAE-E2D2 : 0.15875159289268734
Day 4 :
MAE-E1D1 : 0.16539402954977084, MAE-E2D2 : 0.16673676071107582
Day 5 :
MAE-E1D1 : 0.16949716272784246, MAE-E2D2 : 0.17063818147683252
IND.2
Day 1 :
MAE-E1D1 : 0.0710885461311428, MAE-E2D2 : 0.07079118672775456
Day 2 :
MAE-E1D1 : 0.07985194428287154, MAE-E2D2 : 0.07748176526390453
Day 3 :
MAE-E1D1 : 0.0854636775923968, MAE-E2D2 : 0.08299859596065504
Day 4 :
MAE-E1D1 : 0.0882332985987768, MAE-E2D2 : 0.08443187568916721
Day 5 :
MAE-E1D1 : 0.09076995515531273, MAE-E2D2 : 0.08585589801614049
T.MIN
Day 1 :
MAE-E1D1 : 0.12947372942288168, MAE-E2D2 : 0.13142280593030686
Day 2 :
MAE-E1D1 : 0.15197962835745546, MAE-E2D2 : 0.15341848565558663
Day 3 :
MAE-E1D1 : 0.162795914776204, MAE-E2D2 : 0.16349701241098136
Day 4 :
MAE-E1D1 : 0.16716887079652246, MAE-E2D2 : 0.16748711679387449
Day 5 :
MAE-E1D1 : 0.17005420679692593, MAE-E2D2 : 0.17034509361844594
T.MIN.G
Day 1 :
MAE-E1D1 : 0.20059115168468492, MAE-E2D2 : 0.19822965409102764
Day 2 :
MAE-E1D1 : 0.22191297463551657, MAE-E2D2 : 0.22105030430725828
Day 3 :
MAE-E1D1 : 0.22813145943950772, MAE-E2D2 : 0.2277492541219974
Day 4 :
MAE-E1D1 : 0.23071047852604046, MAE-E2D2 : 0.2301128151892642
Day 5 :
MAE-E1D1 : 0.2318879832054546, MAE-E2D2 : 0.23180336898038414
MAE-E1D1 : 0.2210972135857277
MAPE-E1D1 : inf
RMSE-E1D1 : 0.5905665027284146
MAE-E2D2 : 0.21918585763242307
MAPE-E2D2 : inf
RMSE-E2D2 : 0.5937227770902509




