
1. 什么是迁移学习?
在之前的深度学习用于手写数字的识别中,我们搭建好深度神经网络模型后,需要花费大量的算力和时间去训练模型和优化参数,如果得到的模型只能解决这一个问题,性价比非常低。如果能对一个训练好的模型进行细微调整,就能将其应用到相似的问题中;另外,对于原始数据较少的问题,采用迁移学习方法也能得到较好的效果。
在使用迁移学习的过程中有时会导致迁移模型出现负迁移,我们可以将其理解为模型的泛化能力恶化。假如我们将迁移学习用于解决两个毫不相关的问题,则 极有可能使最后迁移得到的模型出现负迁移。
2. 迁移 VGG16
在这里我们使用迁移学习来解决猫狗分类问题,我们使用的数据集是 kaggle 上的猫狗分类数据集,下载地址:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data
这时候,我们不需要搭建自己的模型,而是通过下载 VGG16 模型,然后在其基础上进行迁移学习。
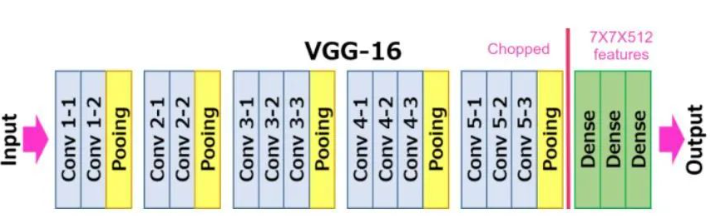
2.1 下载 VGG16 模型
import torch
import torchvision
from torchvision import datasets,models,transforms
import os
from torch.autograd import Variable
import matpolib.pyplot as plt
import time
model = models.vgg16(pretrained=True)
尽管迁移学习要求我们需要解决的问题之间最好具有很强的相似性,但是每个问题对最后输出的结果会有不一样的要求,而承担整个模型输出分类工作的是卷积神经网络模型中的全连接层,所以 在迁移学习的过程中调整最多的也是全连接层部分。其基本思路是冻结卷积神经网络中全连接层之前的全部网络层次,让这些被冻结的网络层次中的参数在模型的训练过程中不进行梯度更新,能够被优化的参数仅仅是没有被冻结的全连接层的全部参数。
比如说,迁移过来的VGG16架构模型最后的输出结果是1000个,而我们的猫狗识别问题只需要输出2个,所以我们需要将最后的全连接层进行修改,使其输出2个结果。
for parma in model.parameters():
parma.requires_grad = False
model.classifier = nn.Sequential(
torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 2)
)
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.classifier.parameters())
print(model)
在这段代码中,对原模型中的参数进行遍历操作,但是将参数中的parma.requires_grad设置为False,这样就可以将这些参数冻结起来,不参与训练。
然后定义新的全连接层结构并重新赋值给model.classifier,最后定义损失函数和优化器。在完成了新的全连接层定义之后,全连接层的parma.requires_grad默认为True,所以在训练的过程中,只有全连接层的参数会被更新。
新的分类器是一个由三个全连接层组成的序列,其中第一个全连接层的输入大小为25088,输出大小为4096;第二个全连接层的输入大小为4096,输出大小为4096;第三个全连接层的输入大小为4096,输出大小为2,表示最终分类的类别数目为2。每个连接层后面都跟着一个ReLU激活函数和一个Dropout层,Dropout层的参数p设置为0.5,表示在训练过程中每个神经元有50%的概率被随机丢弃,这样可以有效地防止过拟合。 输出结果如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
)
)
模型训练
data_dir = './data'
data_trans
data_transform中,定义了数据预处理的操作,包括将图像尺寸调整为[224, 224],将图像转换为张量,并对每个通道进行归一化(均值为0.5,方差为0.5)。这些操作都被包含在了transforms.Compose中。




